Und zum Schluss…
Letzte Lektion. Hier gehts um die Zukunft. Wir sprechen über Linked Data, und haben freie Wahl bezüglich was wir auch immer wissen wollen über den Bibliotheks- und Archivinformatikbereich. Eine weitere Kommilitonin zeigt ausserdem, wie die ALMA-Bedienungsoberfläche aussieht, welches eben in Swisscovery verwendet wird, sowie was ihrer Meinung nach die Unterschiede zu Aleph sind. Vorgestellt werden dann noch Praxisberichte, bei denen die Dozenten mitgearbeitet haben,
Marktüberblick
Die anderen kommerziellen neueren Discovery-Systeme, wie z.B. eben Primo VE, oder Summon (ebenfalls von der Ex Libris), können mit elektronischen Ressourcen besser umgehen als mit den älteren wie Aleph. Das e-Ressourcenmanagement dieser Software erlaubt es, ganze Pakete von Daten gleichzeitig zu katalogisieren, anstatt dass man jedes Dokument einzeln erfassen und eintragen muss. Egal ob man hierbei Primo VE oder VuFind installiert, generall kauft man hierbei einen Artikel-Index (wie z.B. den Primo Central Index), welches angibt, was es bereits schon für existierende elektronische Ressourcen gibt. Diese bezieht man von zentralen Servern, die damit immer das gleiche ausgeben, was sich von älteren Bibliothekssoftware wie Aleph unterscheidet, mit der man seinen eigenen Katalog erstellt. Es gibt Versuche, open data-Central Indices zu erstellen wie das find in catalog (finc) oder die Literaturdatenbank k10plus.
In den allermeisten Fällen beziehen die Central Indices den Grossteil ihrer Datensätze von der crossref, wo all die digital object identifier (DOI) vergeben werden.
Linked Data-orientierte Metadaten
BIBFRAME (Bibliographic Framework)
Dies ist der Name einer Initiative und eines Formats. Es soll die Nachfolge von Marc21 sein, und für das aufkommende Semantic Web geeignet sein, weil es den Linked Data-Paradigmen folgt. Seit 2016 existiert die neue Version Bibframe 2.0.
BIBFRAME ist etwas schlanker, als es die Vorgaben von der Functional Requirements for Bibliographic Records (FRBR) und Resource Description and Access (RDA) angeben. Es ist in RDF verfasst, sprich, einer Tripel-Aussage, dass aus Subjekt, Prädikat und Objekt-Entitäten besteht.
| Subject | Predicate | Object |
|---|---|---|
| http://example.org/Charles_Winkler | http://example.org/wrote | https://charleswinkler.github.io/ |
Tabelle 1: RDF-Tripel-Beispiel
Dies erlaubt es, einen Autor z.B. nur einmal beschreiben zu müssen und in Beziehung zu allerlei Objekten zu setzen, während man in Marc21 klassisch in jedem Datensatz jedesmal bei den Metadaten den Namen des Autors wieder und wieder eingibt für jedes Werk, dass dieser erstellt hat. BIBFRAME besteht aus zwei Komponenten: Dem Datenmodell namens BIBFRAME Model, und der dazugehörigen Ontologie BIBFRAME Vocabulary, wo man die Beschreibungsklassen wiedergibt. Im Model werden die drei Konzepte Work, Instance und Item vorgestellt und unterschieden (siehe Abbildung 1).
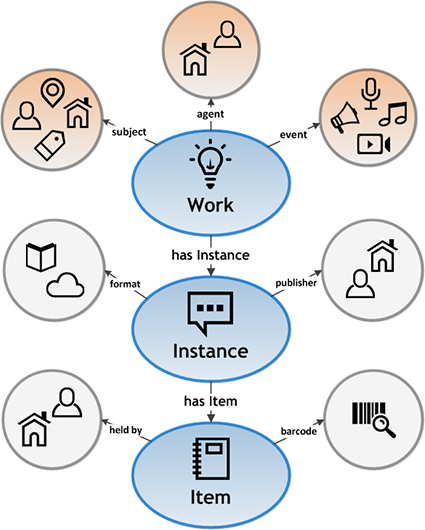
Abbildung 1: Datenebene von BIBFRAME
Auf der Ebene Werk definiert man im Datenmodell dann die Entitäten Agent, Subject und Events folgendermassen:
- Agent sind die Körperschaften, die zur Entstehung des Werk beigetragen haben.
- Subject ist der eigentliche Inhalt des Werks.
- Events sind Sachen, die Inhalte des Werks wiedergeben, wie z.B. ein Filmausschnitt.
Weiterführende Links zu FRBR, RDA und MARC21.
Records in Context (RiC)
RiC ist praktisch das gleiche wie BIBFRAME, einfach für das Archivwesen. Wir erfahren, dass einer unserer anderen Dozenten von der Fachhochschule Graubünden an der Schweizer Entsprechung mitarbeitet. Weil die bereits bestehenden Formate ISAD(G) und EAD eher problematisch sind, und die anderen Archivformate sich scheinbar nie richtig durchsetzen konnte, hat sich die Archivarische Community entschieden, dass man definitiv auf RiC umwechseln sollte. Dies wird mit grösster Wahrscheinlichkeit ein Umdenken erfordern, wie man die Objekte erschliesst, da sie neue und mehrfache Beziehungen ermöglichen sollen, wie man es in Linked Data erwartet. Da Bibliothken und Archive mittels Linked Data arbeiten, kann es sein, dass sie vielleicht näher zusammenkommen, anstatt getrennt zu bleiben.
Fazit hier
Es ist klar, dass vor allem die Crosswalks für Marc21 und EAD in die neuen Formate BIBFRAME und RiC für die nächsten paar Jahre eine wichtige Rolle spielen werden, da man all die bestehenden Datensätze nicht nochmals komplett neu erstellen will.